Understand AI-generated code
Compare. Diagnose. Improve.
An AI-native platform for evaluating and refining LLM-generated workflows with functional abstraction and evidence-first diagnostics.
AI ships code fast.
Verification is still manual.
The generation gap is solved. The verification gap is not.
Multiple models, no clear comparison
01Different models produce different implementations. Existing tools provide outputs — not evidence.
Manual verification is expensive
02AI rewrites large code blocks, but developers still review line by line. Verification becomes the new bottleneck.
Passing tests ≠ quality code
03Readability, efficiency, and trust remain invisible. Current evaluation focuses only on functional correctness.
Core Capabilities
A platform for understanding, comparing, diagnosing, and improving AI-generated code.
Understand the Code
Turn raw generations into structured functional blocks to reason about behavior fast.
Compare Across Models
See structural differences across models without reading full code line-by-line.
Multi-dimensional Evaluation
Evaluate correctness, readability, efficiency, and reusability—beyond tests.
Guided Refinement
Apply targeted fixes with guided prompts powered by diagnostics.
Experiment History
Track runs, settings, and outcomes—revisit insights without repeating work.
Easy to start.
Follow a guided flow to generate results in seconds —
with annotation and diagnosis you can toggle anytime.
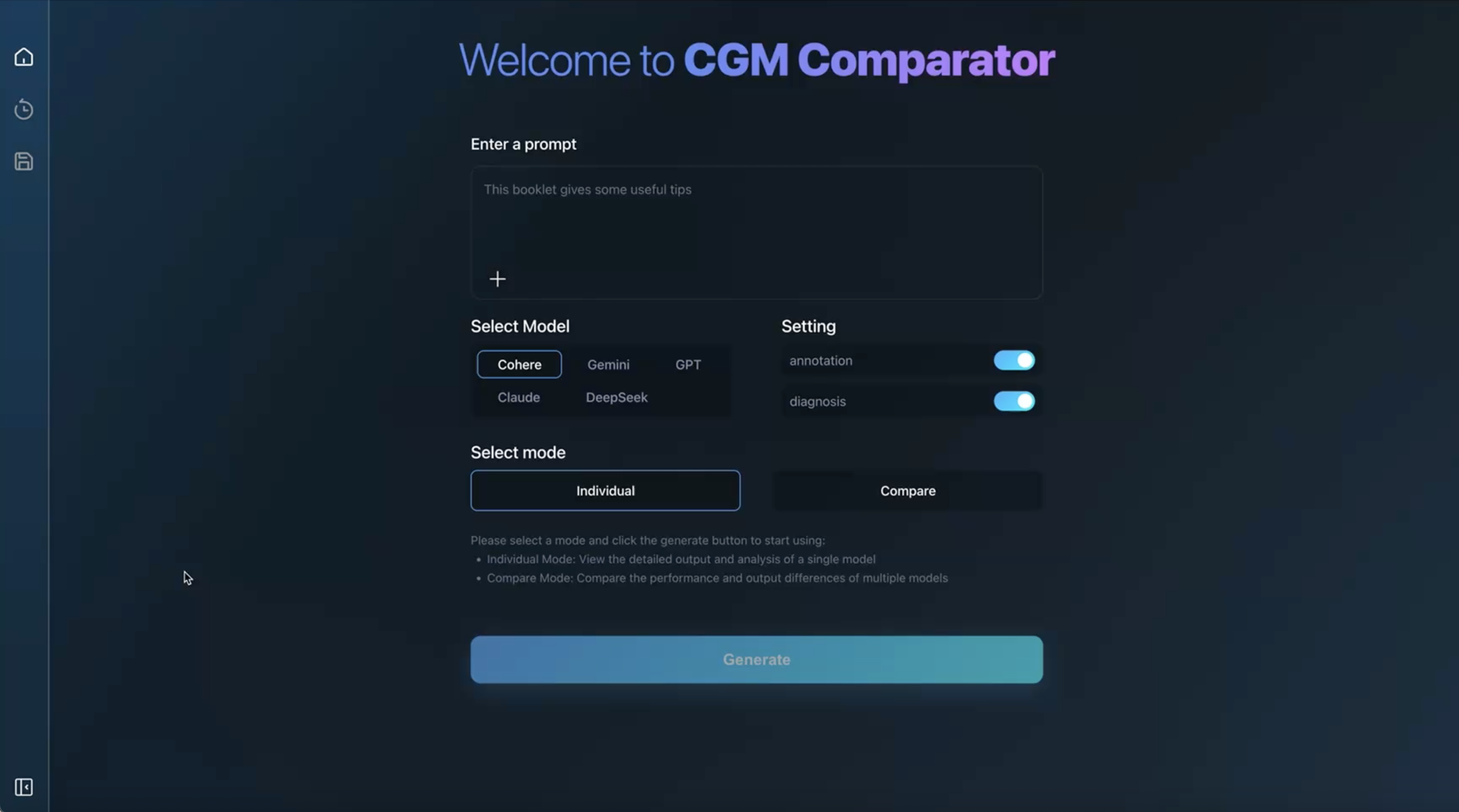
Enter a prompt
Describe your data science task. CGM Comparator extracts intent before you compare outputs.
See how CGM Comparator
works in practice
Explore how the system analyzes, compares, and improves AI-generated workflows.
Compare implementations at a functional level
Understand how different models solve the same task — not just what they output.
- Structural comparison across models
- Functional block alignment
- Multi-dimensional evaluation signals
Reveal workflow structure and intent
Automatically segment generated code into functional units and expose execution logic.
- Functional abstraction beyond syntax
- Structured annotation pipeline
- Clear execution flow
Improve results with structured guidance
Turn diagnosis into actionable steps and refine code iteratively.
- Evidence-based diagnosis
- Guided improvement steps
- Iterative refinement loop
Functional but high cyclomatic complexity. Nested loops, unclear naming.
Logic restructured into named functions. Depth reduced from 5→2.
Vectorized inner loop. Memory cut 40%. All 50 test cases pass.
How the platform works end-to-end
A full-stack loop from prompt to evidence, diagnosis, and continuous improvement.
Interaction Layer
Where developers interact with generated code and insights.
Evaluation Engine
Multi-dimensional analysis and functional understanding of generated code.
Execution + Storage Infrastructure
Sandbox execution, result persistence, and history tracking.
Real scenarios. Real decisions.
From vendor selection to production review — CGM Comparator fits into the moment when AI code quality actually matters.
Know which model to use before you commit.
- Run the same prompt across GPT-4o, Claude, and Gemini simultaneously
- Score each output on Correctness, Readability, Efficiency, and Coherence
- Pick the winner with data — not gut instinct
Engineering Impact
Measured improvements from system design decisions.
Structured function-level annotations generated by a multi-step agent pipeline help users reason about model behavior across alternative implementations.
validated through controlled user studyInteractive comparison workflows reduce manual verification effort and accelerate decision-making under real usage constraints.
measured in real task scenariosValidated against HumanEval benchmarks.
Cold-start execution environment.
OpenAI, Anthropic, Google, Cohere and more.
Static + dynamic execution analysis.
Build trust in AI code,
at any scale.
Start for free. Upgrade when your team needs structured AI code evaluation at production scale.
Explore the platform. Validate your first AI-generated workflows.
For engineers who ship AI-assisted code and need structured verification daily.
For engineering teams evaluating models and agents at scale.
Full plan comparison
Ready to verify
what AI writes?
Start for free. No credit card. Bring your first AI-generated code in under 60 seconds.